Introduction
As large-scale training datasets proved essential for generalization in AI models, synthetic data generation has become increasingly important in domains where data at scale is unavailable. In video understanding tasks, particularly those involving human motion, synthetic data generation often suffers from uncanny features, diminishing its effectiveness for training. Tasks such as sign language translation, gesture recognition, and human motion understanding in autonomous driving have thus been unable to exploit the full potential of synthetic data.
Recent work has focused on bridging classic computer graphics approaches with generative AI techniques, leveraging the versatility and photorealistic content generation capabilities of generative models while grounding them in physical models of the human body that provide full control over the resulting action. Our method employs a modified ExAvatar 3D Gaussian framework as our avatar animation backbone to generate synthetic human action videos.

Representative examples of synthetic human action videos generated using our method, placing a diverse set of novel identities into scenes outside of the original dataset distribution.
Method
Our method extends existing datasets by using real videos as reference human actions that are reenacted by novel identities in new settings. The method consists of three main stages: (1) avatar creation, (2) reference video preparation, and (3) animation.
Avatar Creation
For each novel human identity, we create an expressive whole-body avatar using ExAvatar, which yields fully controllable 3D Gaussian avatars. We extract multiple features including 3D pose meshes (SMPL-X), depth maps, body keypoints, identity segmentation masks, facial expressions, and hand poses.
Animation
With the set of novel identity avatars and reference video features, we generate synthetic videos. For each training video and each novel identity avatar, we first generate white-background videos, then add image backgrounds to create the final synthetic videos with diverse settings.
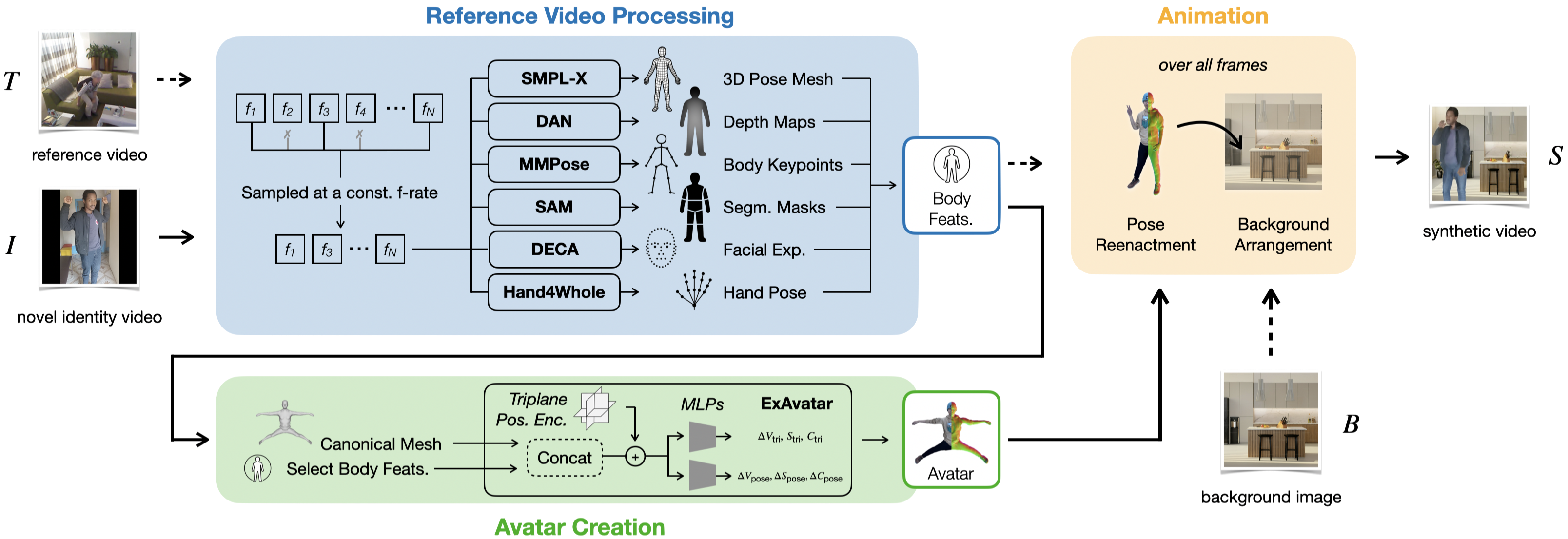
Overview of our method for synthetic human action video data generation. The method takes reference videos T, novel identity videos I, and background images B as input, and generates synthetic videos where identities are animated to reenact actions from reference videos.
RANDOM People Dataset
We introduce the RANDOM People dataset (Reconstructed AI-generated Neural Dataset Of Motion), which contains synthesized videos, novel human identity videos along with their avatars, and scene background images. The dataset includes recordings of 188 participants crowd-sourced through Prolific, filtered to 100 high-quality videos that met our criteria.
The participants were chosen from a stratified sample of residents of the United States. The dataset contains 41 people who identify as male and 59 people who identify as female, with diverse racial representation and ages ranging from 19 to 64 years.

Representative frames from the novel human identity videos in the RANDOM People dataset. Participants performed three slow 360 rotations with varying hand positions.
Experiments and Results
We conducted three sets of experiments—baseline, one-shot, and few-shot—on both Toyota Smarthome and NTU RGB+D datasets using ResNet and SlowFast architectures.
Baseline Experiments
Our results demonstrate significant improvements when incorporating synthetic data. ResNet achieved accuracy improvements from 20% to 51% on Toyota Smarthome and from 9% to 43% on NTU RGB+D. SlowFast showed similar improvements, going from 38% to 56% on Toyota Smarthome and from 27% to 36% on NTU RGB+D.
| Method |
Original |
Synthetic |
Toyota |
NTU RGB+D |
| ResNet |
✓ |
|
20.46 |
08.66 |
| ResNet |
✓ |
✓ |
51.15 |
42.98 |
| SlowFast |
✓ |
|
38.35 |
26.75 |
| SlowFast |
✓ |
✓ |
55.64 |
36.29 |
Few-shot and One-shot Learning
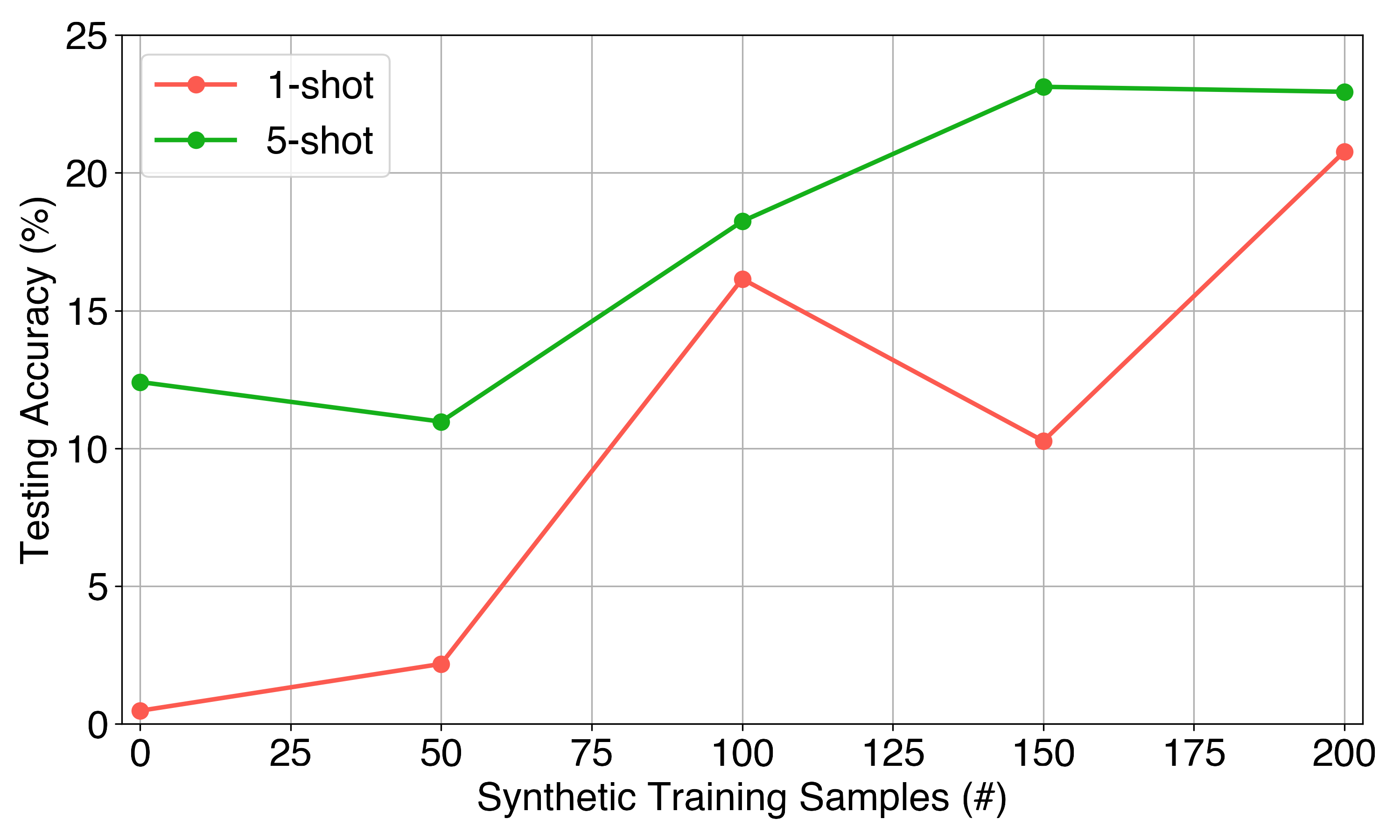
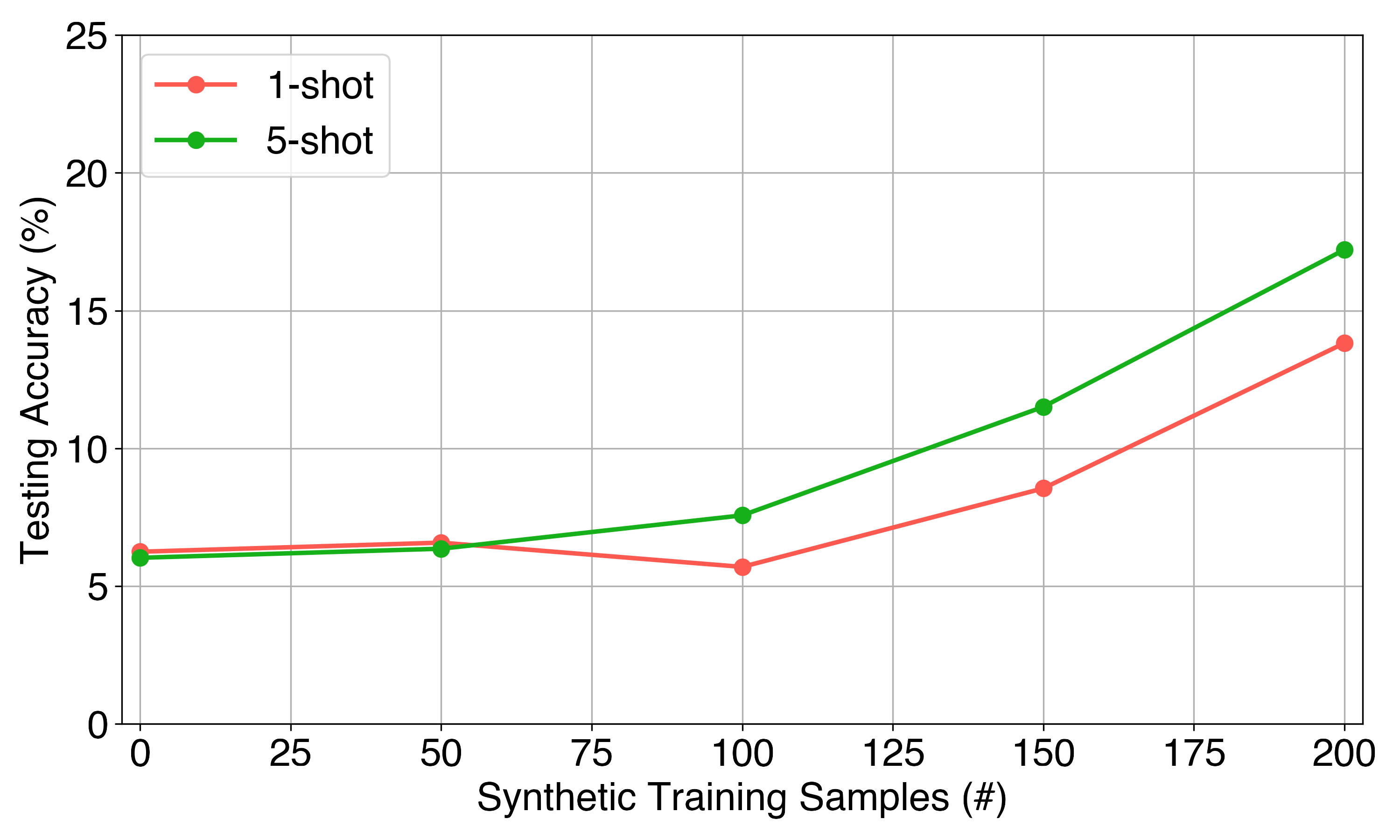
Our synthetic data proves particularly effective for few-shot learning scenarios. With Toyota Smarthome, performance improved from 13% to 23% in few-shot settings. For NTU RGB+D, performance improved from 7% (chance level) to 23% at the highest synthetic sample count.
Qualitative Results
We provide qualitative evaluation of our synthetic videos. Most synthetic videos were consistent with the source videos in terms of pose and scene placement. However, in some cases, the generated videos deviated from the source poses and scene alignment due to limitations in the pose transfer framework.
Limitations
Our method has several limitations that can be categorized into those stemming from the pose transfer framework and those introduced by our method. The ExAvatar framework cannot generate videos with multiple people or convincingly handle actions involving object interactions. Our method may generate physically implausible poses when superimposed on background images and may place actions in inappropriate settings.
Conclusion
We introduce a novel framework for synthetic data generation of human action videos by leveraging a modified ExAvatar framework for 3D Gaussian avatar animation. Our method reenacts human actions from reference videos using novel human identities in varied settings, addressing limitations in photorealism and semantic control that have hindered previous synthetic data generation methods.
We demonstrate notable improvements in action recognition performance across baseline, one-shot, and few-shot learning scenarios on Toyota Smarthome and NTU RGB+D datasets. We also present the RANDOM People dataset, which contains synthetic videos, novel human identity videos along with their avatars, and scene background images, all open-sourced for the research community.
Citation
@inproceedings{knapp2025synthetic,
title={Synthetic Human Action Video Data Generation with Pose Transfer},
author={Knapp, Vaclav and Bohacek, Matyas},
booktitle={Synthetic Data for Computer Vision Workshop @ CVPR 2025}
}